


Apache Kafka is an open source distributed event streaming platform used for high performance data pipelines. It can be used for real-time / batch data processing. Typical kafka system looks like

Why we need kafka?
Note: Skip this section if you already know what kafka is and benefits of using kafka😅
Think differently about how data is managed and how extract, transform and load (ETL) technologies are used to.
Earlier, we use to have operational database and on regular intervals we had to transform the data and load into a data warehouse where we can further use it.


But now databases are augmented / replaced by distributed data systems, where we have multiple databases / datasources like Mongodb, Casandradb, Hadoop, etc. to store the data based on the requirements of each system.
ETL tools will have to handle more than databases and data warehouses in case of distributed systems. ETL tools were build to process data in batch fashion. They are resource intensive and time taking processes.
With this new era, applications not only collects the operational data but there are lot of meta data like logs, analytics collected by each of the system.
Also the rise of stream data is increasing where we need to process data on the go instead of processing it in batches.
With this new world of data streaming, we need to ability to process high volume and highly diverse data. Data usually flows in form of events. Consider we have event center which gathers events from different sources and shares with various data sources

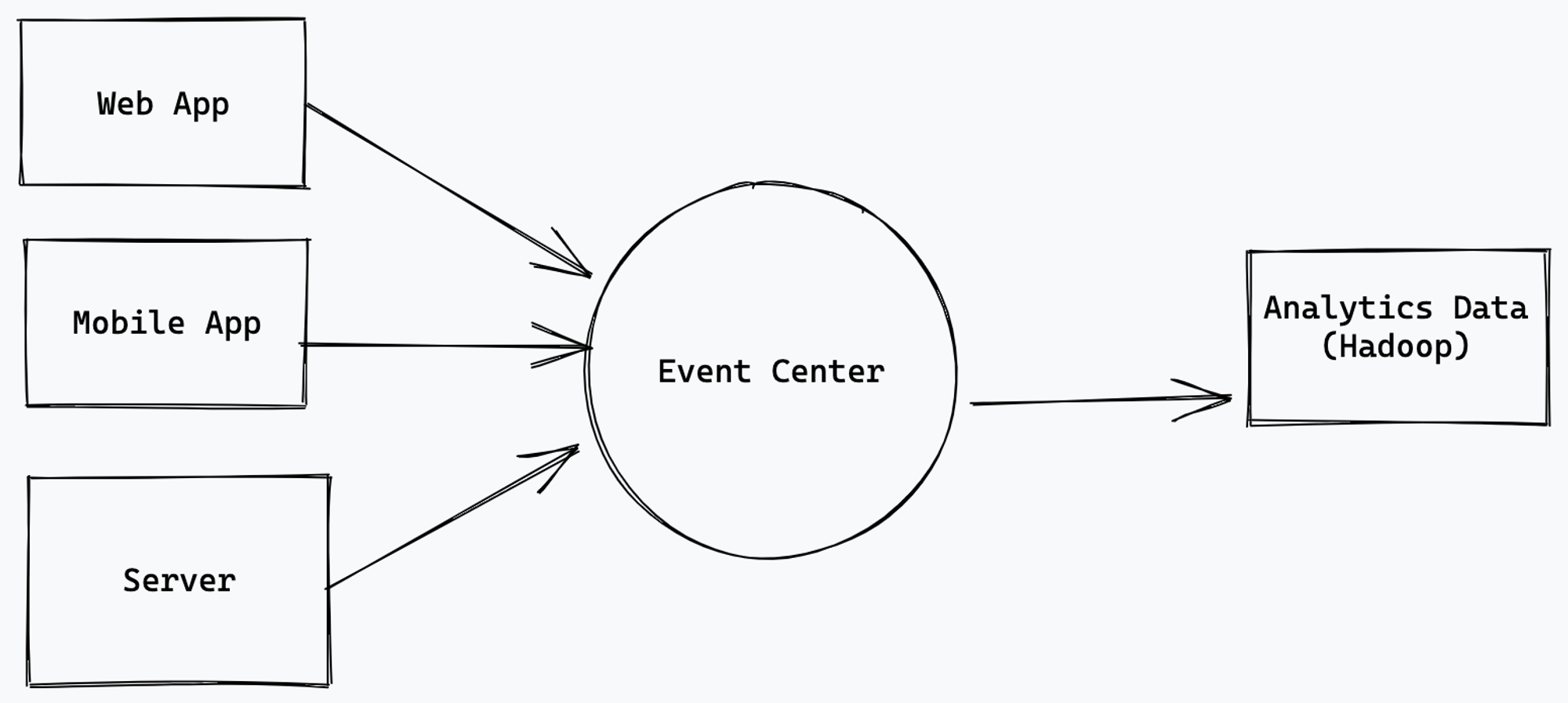
Kafka plays this role of Event Center, where data is queued and stored till consumed by consumer.
Benefits of using Kafka
- In case of consumer failures data can be re-gained
- Reduce the cost of ETL as now consumer itself can decided how to use this data
- Asynchronously stream the data
- Can process high volume and diverse data while streaming itself.
For more information you can check this amazing talk by Neha Narkhede on how to think about the data while designing large scale application and how to use Kafka.
Alright lets start building our Analytics System using Kafka. To simplify the example, we will be recording page events from the website and save them to Postgres db. Our system design will look like

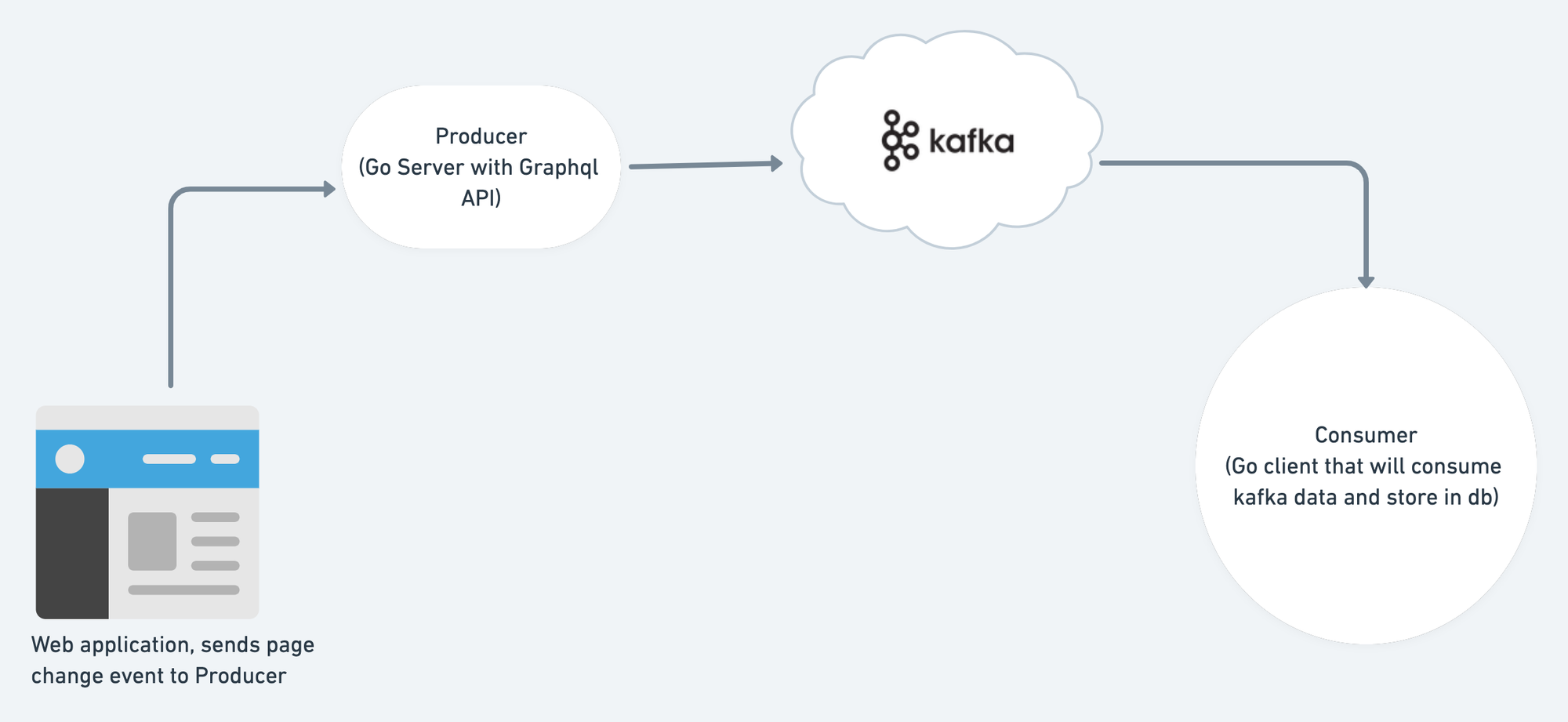
Step 1: Setup Kafka Server
For this demo we will be using docker to run kafka server. But for production you can use Confluent or any other hosted service.
- Create
analytics-system/docker-compose.yaml
- Paste the following content in
docker-compose.yaml
version: "3" services: zookeeper: image: wurstmeister/zookeeper container_name: zookeeper ports: - 2181:2181 kafka: image: wurstmeister/kafka container_name: kafka ports: - 9092:9092 environment: KAFKA_ADVERTISED_HOST_NAME: localhost KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
- Start kafka server:
docker-compose up
Step 2: Bootstrap Project
- Create repo
mkdir analytics-system
- Change working dir
cd analytics-system
- Create producer dir
mkdir producer && cd producer
- Init producer project
go mod init producer
- Create consumer dir
cd .. && mkdir consumer && cd consumer
- Init consumer project
go mod init consumer
Step 3: Create Producer
Create Graphql Server using gqlgen
- Change to producer dir
cd analytics-system/producer
- Download the dependency:
go get github.com/99designs/gqlgen
- Initialise Project:
go run github.com/99designs/gqlgen init
Note: if you get validation failed error install the dependencies mentioned in the error: example go get github.com/vektah/gqlparser/v2@v2.1.0
- Start and test graphql server
go build && ./producer
- Replace the initial boilerplate graphql file with following
analytics-system/producer/graph/schema.graphqlsscalar Int64 type Event { id: ID! eventType: String path: String search: String title: String url: String userId: String } type PingResponse { message: String! } input RegisterKafkaEventInput { eventType: String! userId: String! path: String! search: String! title: String! url: String! } type Mutation { register_kafka_event(event: RegisterKafkaEventInput!): Event! } type Query { ping: PingResponse! }
Here we are defining mutation and types required to produce page view event.
- Clear content of
analytics-system/producer/graph/schema.resolvers.go
echo "" > graph/schema.resolvers.go
- Generate new resolvers and query as per the graphql file defined above.
go run github.com/99designs/gqlgen generate
- Replace
pingquery resolver to returnHello worldor some string.
Note this step is just to test if our server starts correctly
Update
Ping resolver in graph/schema.resolvers.go with following contentfunc (r *queryResolver) Ping(ctx context.Context) (*model.PingResponse, error) { res := &model.PingResponse{ Message: "Hello world", } return res, nil }
- Build and test server
go build && ./producer
- Hit
http://localhost:8080in your browser and test the ping query
query { ping { message } }
Setup Kafka Producer using confluent-kakfka-go
- Install dependencies:
go get -u gopkg.in/confluentinc/confluent-kafka-go.v1/kafka
Note: Latest version of confluent-kafka-go doesn't require librdkafka, but in case if you face any errors check the following link and install the require dependencies https://github.com/confluentinc/confluent-kafka-go#installing-librdkafka
- Setup kafka topic:
Add following util in
graph/schema.resolvers.go. This function will make sure that topic is always created// function to create topic // sample usage CreateTopic("PAGE_VIEW") func CreateTopic(topicName string) { a, err := kafka.NewAdminClient(&kafka.ConfigMap{"bootstrap.servers": "localhost"}) if err != nil { panic(err) } defer a.Close() maxDur, err := time.ParseDuration("60s") if err != nil { panic("ParseDuration(60s)") } ctx := context.Background() results, err := a.CreateTopics( ctx, // Multiple topics can be created simultaneously // by providing more TopicSpecification structs here. []kafka.TopicSpecification{{ Topic: topicName, NumPartitions: 1, }}, // Admin options kafka.SetAdminOperationTimeout(maxDur)) if err != nil { log.Printf("Failed to create topic: %v\\n", err) } log.Println("results:", results) }
A Topic is a category/feed name to which records are stored and published
- Produce Kafka Event
Replace
RegisterKafkaEvent resolver function in graph/schema.resolver.go with followingfunc (r *mutationResolver) RegisterKafkaEvent(ctx context.Context, event model.RegisterKafkaEventInput) (*model.Event, error) { p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "localhost"}) if err != nil { panic(err) } defer p.Close() // Delivery report handler for produced messages go func() { for e := range p.Events() { switch ev := e.(type) { case *kafka.Message: if ev.TopicPartition.Error != nil { fmt.Printf("Delivery failed: %v\\n", ev.TopicPartition) } else { fmt.Printf("Delivered message to %v\\n", ev.TopicPartition) } } } }() // Produce messages to topic (asynchronously) topic := event.EventType CreateTopic(topic) currentTimeStamp := fmt.Sprintf("%v", time.Now().Unix()) e := model.Event{ ID: currentTimeStamp, EventType: &event.EventType, Path: &event.Path, Search: &event.Search, Title: &event.Title, UserID: &event.UserID, URL: &event.URL, } value, err := json.Marshal(e) if err != nil { log.Println("=> error converting event object to bytes:", err) } p.Produce(&kafka.Message{ TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, Value: []byte(value), }, nil) // Wait for message deliveries before shutting down p.Flush(15 * 1000) return &e, nil }
- Test the event produced:
go build && ./producer
- Hit localhost:8080 in browser and test following mutation
mutation { register_kafka_event(event: { eventType: "PAGE_VIEW", userId: "some_session_id", path: "/test", search: "?q=foo" title: "Kafka Demo", url: "kafka.demo.com" }) { id eventType } }
Hurray! 🚀 our producer is ready 🎉
Step 4: Create Consumer
We have already setup consumer project in
analytics-system/consumer. Here in consumer we will listen to events produced by Kafka server in step 3 and save it into postgres db.Note you can process & transform this data based on system that you want to store into.
To simplify the process we will be using
gorm a SQL ORM(object relational model) for Golang.Setup gorm and event schema
Note: make sure you are in consumer dir: cd analytics-system/consumer
- Install dependencies:
go get -u gorm.io/gorm go get -u gorm.io/driver/postgres
- Create
main.gofile:touch analytics-system/consumer/main.go
- Connect to db in
main.goand setup Event Schema
Note: for this example we are using local postgres instance.
analytics-system/consumer/main.gopackage main import ( "log" "gorm.io/driver/postgres" "gorm.io/gorm" "gorm.io/gorm/clause" "gorm.io/gorm/schema" ) type Event struct { ID string `gorm:"primaryKey"` UserID string EventType string Path string Search string Title string URL string CreatedAt int64 `gorm:"autoCreateTime"` // same as receivedAt UpdatedAt int64 `gorm:"autoUpdateTime"` } func SaveEvent(db *gorm.DB, event Event) (Event, error) { result := db.Clauses( clause.OnConflict{ UpdateAll: true, Columns: []clause.Column{}, }).Create(&event) if result.Error != nil { log.Println(result.Error) return event, result.Error } return event, nil } func main() { dbURL := `postgres://localhost:5432/postgres` ormConfig := &gorm.Config{ NamingStrategy: schema.NamingStrategy{ TablePrefix: "kafka_", }, } db, err := gorm.Open(postgres.Open(dbURL), ormConfig) if err != nil { panic(`Unable to connect to db`) } log.Println("=>Connected to successfully:", db) err = db.AutoMigrate(&Event{}) if err != nil { log.Println("Error migrating schema:", err) } }
Setup kafka Consumer code
- Install dependencies:
go get -u gopkg.in/confluentinc/confluent-kafka-go.v1/kafka
- Update
main.gowith following content
package main import ( "encoding/json" "fmt" "log" "github.com/confluentinc/confluent-kafka-go/kafka" "gorm.io/driver/postgres" "gorm.io/gorm" "gorm.io/gorm/clause" "gorm.io/gorm/schema" ) type Event struct { ID string `gorm:"primaryKey"` UserID string EventType string Path string Search string Title string URL string CreatedAt int64 `gorm:"autoCreateTime"` // same as receivedAt UpdatedAt int64 `gorm:"autoUpdateTime"` } func SaveEvent(db *gorm.DB, event Event) (Event, error) { result := db.Clauses( clause.OnConflict{ UpdateAll: true, Columns: []clause.Column{}, }).Create(&event) if result.Error != nil { log.Println(result.Error) return event, result.Error } return event, nil } func main() { dbURL := `postgres://localhost:5432/postgres` ormConfig := &gorm.Config{ NamingStrategy: schema.NamingStrategy{ TablePrefix: "kafka_", }, } db, err := gorm.Open(postgres.Open(dbURL), ormConfig) if err != nil { panic(`Unable to connect to db`) } log.Println("=> Connected to db successfully", db) err = db.AutoMigrate(&Event{}) if err != nil { log.Println("Error migrating schema:", err) } c, err := kafka.NewConsumer(&kafka.ConfigMap{ "bootstrap.servers": "localhost", "group.id": "myGroup", "auto.offset.reset": "earliest", }) if err != nil { panic(err) } c.SubscribeTopics([]string{"PAGE_VIEW"}, nil) for { msg, err := c.ReadMessage(-1) if err == nil { fmt.Printf("Message on %s: %s\\n", msg.TopicPartition, string(msg.Value)) var event Event err := json.Unmarshal(msg.Value, &event) if err != nil { log.Println("=> error converting event object:", err) } _, err = SaveEvent(db, event) if err != nil { log.Println("=> error saving event to db...") } } else { // The client will automatically try to recover from all errors. fmt.Printf("Consumer error: %v (%v)\\n", err, msg) } } }
- Test consumer:
go build && ./consumer
Step 5: Test the flow
- Start kafka server if you don't have it running:
docker-compose up
- Start producer
cd analytics-system/producer && go build && ./producer
- Start consumer
cd analytics-system/consumer && go build && ./consumer
- Hit http://locahost:8080 in the browser
- Trigger the mutation
mutation { register_kafka_event(event: { eventType: "PAGE_VIEW", userId: "some_session_id", path: "/test", search: "?q=foo" title: "Kafka Demo", url: "kafka.demo.com" }) { id eventType } }
- Check the consumer log. You should be able to see logs for data being saved in postgres.
- Check the postgres data
SELECT * FROM kafka_events;
Hurray! 🚀 thats all our page view analytics event system is ready. 👏
You can check the full code base on github